
NA is synthesized in each NB and PCC tissues, and various members of this synthetic pathway have been reported previously in NB as best scoring classifiers. The significance of this pathway is very well characterized in NB, nevertheless, the expression of numerous of its important mem bers have not been reported in PCC, yet. The homeobox transcription aspect PHOX2B is essen tial for your differentiation and servicing of noradre nergic neurons. PHOX2B mutations are observed in uncommon hereditary kinds of NB and Hirschsprungs disorder. PHOX2B is concerned during the transcriptional regula tion of RET expression, nevertheless mutations of PHOX2B in hereditary and sporadic PCC have not been reported, nevertheless. The downstream targets with the master regulators of neural crest derived precursor cell growth PHOX2B and HAND2 are PHOX2A, GATA2, GATA3.
These transcription elements perform critical roles from the expressional selleckchem regulation in the TH and DBH genes. TH catalyzes the charge limiting phase of NA production, and DBH converts dopamine to NA. NA in chromaffin cells is co stored in secretory granules with CGA and CGB molecules. The uptake into granules is mediated by SLC18A1 protein through the cytoplasm and by SLC6A2 from your extracellular area. From the comparison of NB or PCC tissues with other tumors and typical tissues, we’ve got discovered the signifi cant overexpression of all the above stated genes in NB or PCC samples in greater than 90 comparisons. This observation highlights the common origin of NB and PCC, nonetheless, it really is surprising that you’ll find only extremely number of data over the expression of those genes in PCC.
Similarities amongst NB and PCC To investigate probably the most major similarities amongst NB and PCC tissues, we’ve searched for previously unreported reference genes. By this strategy, by far the most equivalent pathway among NB and PCC was death buy Ibrutinib recep tor signaling. Avoidance of apoptosis is really a vital method of tumorigen esis. Considering the fact that this pathway included essentially the most similar gene expression patterns in NB and PCC, we could conclude that these tumors may use the very same techniques for rescue from programmed cell death. The importance of proteins involved from the regulation of apoptosis triggered by death receptors is already reported in NB. Apoptosis in mammalian cells could be initiated as a result of two major pathways, one particular in volving tumor necrosis aspect alpha and DR1 6, another involving release of cytochrome c from mito chondria as a result of Fas activation.
Numerous reports underline the significance of mitochondria dependent signaling in NB. Fas resistance in NB could create through the inactivation of caspase 8, which can be absent in extra 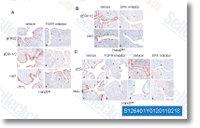 than 1 third of NB cases, and normally methylated in over 60% of PCC. Fas resistance may well even build in caspase eight expressing NB by means of large level expression on the antiapoptotic protein BCL2.
than 1 third of NB cases, and normally methylated in over 60% of PCC. Fas resistance may well even build in caspase eight expressing NB by means of large level expression on the antiapoptotic protein BCL2.
NA is synthesized in each NB and PCC tissues, and various members
Reply
 values, which could be impractical for substantial scale models. Approaches working with GMA kinetics partially stay clear of literature mining. In these approaches, such as MASS modeling, thermodynamic information and facts collected from the litera ture is mixed with experimentally determined me tabolite and/or enzyme concentrations and flux distribu tions to estimate the remaining model parameters.
values, which could be impractical for substantial scale models. Approaches working with GMA kinetics partially stay clear of literature mining. In these approaches, such as MASS modeling, thermodynamic information and facts collected from the litera ture is mixed with experimentally determined me tabolite and/or enzyme concentrations and flux distribu tions to estimate the remaining model parameters.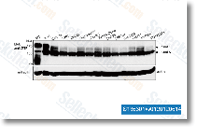 exon but acquiring hits to acknowledged proteins at E value cutoff 1e 5 had been reported as final novel transcripts despite the fact that some of the other sequences could also derived from genes which have not been annotated. Identification of SNPs and indels SAMtools was made use of to analyze the achievable SNPs and indels during the banana genome according to the transcrip tome data. The authentic reads were mapped back for the assembled banana transcripts. The SNPs and indels were referred to as employing the mpileup instrument in SAMtools bundle.
exon but acquiring hits to acknowledged proteins at E value cutoff 1e 5 had been reported as final novel transcripts despite the fact that some of the other sequences could also derived from genes which have not been annotated. Identification of SNPs and indels SAMtools was made use of to analyze the achievable SNPs and indels during the banana genome according to the transcrip tome data. The authentic reads were mapped back for the assembled banana transcripts. The SNPs and indels were referred to as employing the mpileup instrument in SAMtools bundle. contraction, nevertheless they never affect caffeine induced contraction, as a result they advertise vasodilation and hypotension. Tigrin from venom with the Japanese colubrid, Rhabdophis tigrinus, impacted neither. This is often almost certainly mainly because Rhabdophis venom glands are not secretory in nature.
contraction, nevertheless they never affect caffeine induced contraction, as a result they advertise vasodilation and hypotension. Tigrin from venom with the Japanese colubrid, Rhabdophis tigrinus, impacted neither. This is often almost certainly mainly because Rhabdophis venom glands are not secretory in nature.